A few technical details about our PSR server:
1. Currently, only 7 letter DNA sequences (a,c,g,t) are permitted.
2. The method currently defaults to use the
Yeo and Burgereal and
decoy
data sets for human pre-mRNA donor splice sites.
(The YB files list the last three bases of the exon and the first four bases of the intron
after the conserved GT sequence which is omitted; for example,
aagattg is really aagGTattg.)
3. When cross-validating, one-third of the total input data is
randomly selected and reserved for testing;
the remaining data can be used for training.
We have found that it is interesting to study how the performance
of the method scales with training data set size ---
this reveals whether the method's performance has saturated ---
so we allow the
user to specify a percentage (0 to 100 percent) of the data to be
used for training.
4. The performance measure the program reports is the optimal binary
Pearson correlation coefficient between prediction and reality:
,
or the area under a Reciever Operating Characteristic curve
(ROC is the True Positive Rate as a function of False Positive Rate).
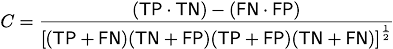 ,
,